Background Context & Theory
This page provides some background and theory to the framework, explaining: the context within which the framework exists; the ideas and principles that it builds upon, what its core values are, its architecture, and how it compares to other architectural approaches other frameworks, and how it can be deployed.
Domain-Driven Design
There’s no doubt that we developers love the challenge of understanding and deploying complex technologies. But understanding the nuances and subtleties of the business domain itself is just as great a challenge, perhaps more so. If we devoted our efforts to understanding and addressing those subtleties, we could build better, cleaner, and more maintainable software that did a better job for our stakeholders. And there’s no doubt that our stakeholders would thank us for it.
A couple of years back Eric Evans wrote his book Domain-Driven Design, judged by many to being a seminal work. In fact, most if not all of the ideas in Evans' book have been expressed before, but what he did was pull those ideas together to show how predominantly object-oriented techniques can be used to develop rich, deep, insightful, and ultimately useful business applications.
There are two central ideas at the heart of domain-driven design.
-
the ubiquitous language is about getting the whole team (both domain experts and developers) to communicate more transparently using a domain model.
-
Meanwhile, model-driven design is about capturing that model in a very straightforward manner in code.
Let’s look at each in turn.
Ubiquitous Language
It’s no secret that the IT industry is plagued by project failures. Too often systems take longer than intended to implement, and when finally implemented, they don’t address the real requirements anyway.
Over the years we in IT have tried various approaches to address this failing. Using waterfall methodologies, we’ve asked for requirements to be fully and precisely written down before starting on anything else. Or, using agile methodologies, we’ve realized that requirements are likely to change anyway and have sought to deliver systems incrementally using feedback loops to refine the implementation.
But let’s not get distracted talking about methodologies. At the end of the day what really matters is communication between the domain experts (that is, the business) who need the system and the techies actually implementing it. If the two don’t have and cannot evolve a shared understanding of what is required, then the chance of delivering a useful system will be next to nothing.
Bridging this gap is traditionally what business analysts are for; they act as interpreters between the domain experts and the developers. However, this still means there are two (or more) languages in use, making it difficult to verify that the system being built is correct. If the analyst mistranslates a requirement, then neither the domain expert nor the application developer will discover this until (at best) the application is first demonstrated or (much worse) an end user sounds the alarm once the application has been deployed into production.
Rather than trying to translate between a business language and a technical language, with DDD we aim to have the business and developers using the same terms for the same concepts in order to create a single domain model. This domain model identifies the relevant concepts of the domain, how they relate, and ultimately where the responsibilities are. This single domain model provides the vocabulary for the ubiquitous language for our system.
Creating a ubiquitous language calls upon everyone involved in the system’s development to express what they are doing through the vocabulary provided by the model. If this can’t be done, then our model is incomplete. Finding the missing words deepens our understanding of the domain being modeled.
This might sound like nothing more than me insisting that the developers shouldn’t use jargon when talking to the business. Well, that’s true enough, but it’s not a one-way street. A ubiquitous language demands that the developers work hard to understand the problem domain, but it also demands that the business works hard in being precise in its naming and descriptions of those concepts. After all, ultimately the developers will have to express those concepts in a computer programming language.
Also, although here I’m talking about the "domain experts" as being a homogeneous group of people, often they may come from different branches of the business. Even if we weren’t building a computer system, there’s a lot of value in helping the domain experts standardize their own terminology. Is the marketing department’s "prospect" the same as sales' "customer," and is that the same as an after-sales "contract"?
The need for precision within the ubiquitous language also helps us scope the system. Most business processes evolve piecemeal and are often quite ill-defined. If the domain experts have a very good idea of what the business process should be, then that’s a good candidate for automation, that is, including it in the scope of the system. But if the domain experts find it hard to agree, then it’s probably best to leave it out. After all, human beings are rather more capable of dealing with fuzzy situations than computers.
So, if the development team (business and developers together) continually searches to build their ubiquitous language, then the domain model naturally becomes richer as the nuances of the domain are uncovered. At the same time, the knowledge of the business domain experts also deepens as edge conditions and contradictions that have previously been overlooked are explored.
We use the ubiquitous language to build up a domain model. But what do we do with that model? The answer to that is the second of our central ideas.
Model-Driven Design
Of the various methodologies that the IT industry has tried, many advocate the production of separate analysis models and implementation models. One example (from the mid 2000s) was that of the OMG's Model-Driven Architecture ( MDA) initiative, with its platform-independent model (the PIM) and a platform-specific model (the PSM).
Bah and humbug! If we use our ubiquitous language just to build up a high-level analysis model, then we will re-create the communication divide. The domain experts and business analysts will look only to the analysis model, and the developers will look only to the implementation model. Unless the mapping between the two is completely mechanical, inevitably the two will diverge.
What do we mean by model anyway? For some, the term will bring to mind UML class or sequence diagrams and the like. But this isn’t a model; it’s a visual representation of some aspect of a model. No, a domain model is a group of related concepts, identifying them, naming them, and defining how they relate. What is in the model depends on what our objective is. We’re not looking to simply model everything that’s out there in the real world. Instead, we want to take a relevant abstraction or simplification of it and then make it do something useful for us. A model is neither right nor wrong, just more or less useful.
For our ubiquitous language to have value, the domain model that encodes it must have a straightforward, literal representation to the design of the software, specifically to the implementation. Our software’s design should be driven by this model; we should have a model-driven design.
Here also the word design might mislead; some might be thinking of design documents and design diagrams, or perhaps of user interface (UX) design. But by design we mean a way of organizing the domain concepts, which in turn leads to the way in which we organize their representation in code.
Luckily, using object-oriented (OO) languages such as Java, this is relatively easy to do; OO is based on a modeling paradigm anyway. We can express domain concepts using classes and interfaces, and we can express the relationships between those concepts using associations.
So far so good. Or maybe, so far so much motherhood and apple pie. Understanding the DDD concepts isn’t the same as being able to apply them, and some of the DDD ideas can be difficult to put into practice. Time to discuss the naked objects pattern and how it eases that path by applying these central ideas of DDD in a very concrete way.
Naked Objects Pattern
Apache Causeway implements the naked objects pattern, originally formulated by Richard Pawson. So who better than Richard to explain the origination of the idea:
The Naked Objects pattern arose, at least in part, from my own frustration at the lack of success of the domain-driven approach. Good examples were hard to find — as they are still.
A common complaint from DDD practitioners was that it was hard to gain enough commitment from business stakeholders, or even to engage them at all. My own experience suggested that it was nearly impossible to engage business managers with UML diagrams. It was much easier to engage them in rapid prototyping — where they could see and interact with the results — but most forms of rapid prototyping concentrate on the presentation layer, often at the expense of the underlying model and certainly at the expense of abstract thinking.
Even if you could engage the business sponsors sufficiently to design a domain model, by the time you’d finished developing the system on top of the domain model, most of its benefits had disappeared. It’s all very well creating an agile domain object model, but if any change to that model also dictates the modification of one or more layers underneath it (dealing with persistence) and multiple layers on top (dealing with presentation), then that agility is practically worthless.
The other concern that gave rise to the birth of Naked Objects was how to make user interfaces of mainstream business systems more "expressive" — how to make them feel more like using a drawing program or CAD system. Most business systems are not at all expressive; they treat the user merely as a dumb process-follower, rather than as an empowered problem-solver. Even the so-called usability experts had little to say on the subject: try finding the word "empowerment" or any synonym thereof in the index of any book on usability. Research had demonstrated that the best way to achieve expressiveness was to create an object-oriented user interface (OOUI). In practice, though, OOUIs were notoriously hard to develop.
Sometime in the late 1990s, it dawned on me that if the domain model really did represent the "ubiquitous language" of the business and those domain objects were behaviorally rich (that is, business logic is encapsulated as methods on the domain objects rather than in procedural scripts on top of them), then the UI could be nothing more than a reflection of the user interface. This would solve both of my concerns. It would make it easier to do domain-driven design, because one could instantly translate evolving domain modeling ideas into a working prototype. And it would deliver an expressive, object-oriented user interface for free. Thus was born the idea of Naked Objects.
You can learn much more about the pattern in the book, Naked Objects, also freely available to read online. Richard co-wrote the book with one of Apache Causeway' committers, Robert Matthews, who was in turn the author of the Naked Objects Framework for Java (the original codebase of Apache Causeway).
You might also want to read Richard’s PhD on the subject.
Object Interface Mapping
Another — more technical — way to think about the naked objects pattern is as an object interface mapper, or OIM.
Just as an ORM (such as EclipseLink or Hibernate) maps domain entities to a database, you can think of the naked objects pattern as representing the concept of mapping domain objects to a user interface.
We sometimes use this idea to explain naked objects to a developer audience.
Core Values
This section describes the core values that the the Apache Causeway framework tries to uphold.
Aligned with the Business
Apache Causeway is primarily aimed at custom-built "enterprise" applications, with a UI provided by the Web UI (Wicket viewer) is intended to be usable by domain experts, typically end-users within the organization.
But why should an organisation build software, when it could just buy it?
To be clear, buying packaged software does make sense in many cases: for statutory requirements, such as payroll or general ledger, or document management/retrieval. But (we argue) it makes much less sense to buy packaged software for the systems that support the core business: the software should fit the business, not the other way around.
Packaged software suffers from the problem of both having doing "too much" and "not enough":
-
it does "too much" because it will have features that are not required by your business. These extra unnecessary features make the system difficult to learn and use.;
-
but it may also do "too little" because there may be crucial functionality not supported by the software.
The diagram below illustrates the dichotomy:
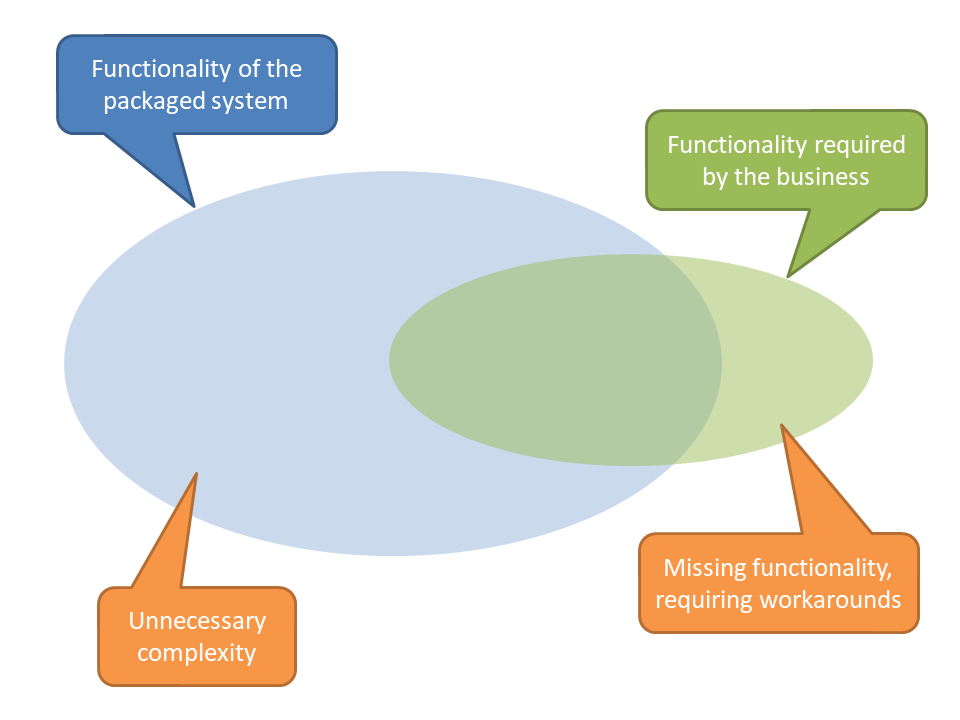
What happens in this case is that end-users — needing some sort of solution for their particular business problem — will end up using unused fields to store the information they need. We end up with no correlation between the fields definitions and the values stored therein, sometimes with the datatypes not even matching. Any business rules pertaining to this extra data have to be enforced manually by the users, rather than by the system. The end result is a system even more complicated to learn and use, with the quality of the data held within it degrading as end users inevitably make mistakes in using it.
There are other benefits too for building rather than buying. Packaged software is almost always sold with a support package, the cover of which can vary enormously. At one end of the spectrum the support package ("bronze", say) will amount to little more than the ability to raise bug reports and to receive maintenance patches. At the other end (let’s call it "platinum"), the support package might provide the ability to influence the direction of the development of the product, perhaps specific features missing by the business.
Even so, the more widely used is the software package, the less chance of getting it changed. Does anyone reading this think they could get a new feature added (or removed) from Microsoft Word, for example?
Here’s another reason why you should build, and not buy, the software supporting your core business domain. Although most packaged software is customisable to a degree, there is always a limit to what can be customised. The consequence is that the business is forced to operate according to the way in which the software requires.
This might be something as relatively innocuous as imposing its own terminology onto the business, meaning that the end-users must mentally translate concepts in order to use the software. But it might impose larger constraints on the business; some packaged software (we carefully mention no names) is quite notorious for this
If your business is using the same software as your competitor, then obviously there’s no competitive advantage to be gained. And if your competitor has well-crafted custom software, then your business will be at a competitive disadvantage.
So, our philosophy is that custom software — for your core business domain — is the way to go.
Modular
Enterprise applications tend to stick around a long time; a business' core domains don’t tend to change all that often. What this means in turn is that the application needs to be maintainable, so that it is as easy to modify and extend when it’s 10 years old as when it was first written.
That’s a tall order for any application to meet, and realistically it can only be met if the application is modular. Any application that lacks a coherent internal structure will ultimately degrade into an unmaintable "big ball of mud", and the development team’s velocity/capacity to make changes will reduce accordingly.
Apache Causeway' architecture allows the internal structure to be maintained in two distinct ways.
-
first, the naked objects pattern acts as a "firewall", ensuring that any business logic in the domain layer doesn’t leak out into the presentation layer (it can’t, because the developer doesn’t write any controllers/views).
-
second, the framework’s provides various features (discussed in more detail below) to allow the different modules within the domain layer to interact with each in a decoupled fashion.
The diagram below illustrates this:
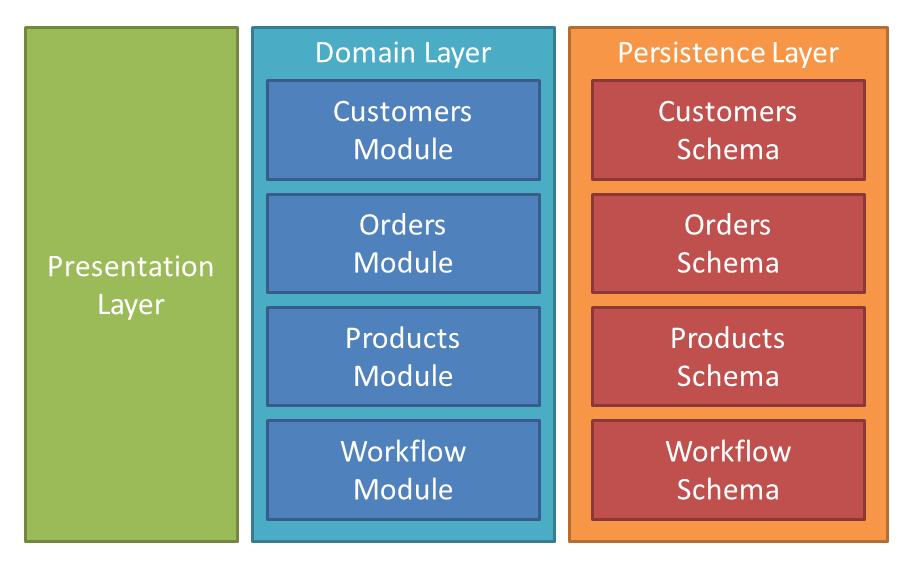
Here, the presentation layer (Wicket UI or REST API) is handled by the framework, while the developer focusses on just the domain layer. The framework encourages splitting this functionality into modules; each such module has its counterpart (typically tables within a given RDBMS database schema) within the persistence layer.
This architecture means that it’s impossible for business logic to leach out into the adjacent presentation layer because the developer doesn’t (can’t) write any code for presentation layer. We in effect have a "firewall" between the two layers.
To support the business domain being split into separate modules, the framework provides various features, the most important of which are the dependency injection of domain services, mixins, and in-memory events.
For those cases where a module needs to interact with other modules but does not know about their implementations, the module can either define its own SPI domain services or it can define custom domain events and fire them. This technique is also used extensively by the framework itself. For example, the EntityPropertyChangeSubscriber SPI enables custom auditing, and the ExecutionSubscriber SPI enables custom publishing.
When building a modular application, it’s important to consider the logical layering of the modules: we don’t need every module to be completely decoupled from every other. The most important requirement is that there are no cyclic dependencies, because otherwise we run the risk of the application degrading into a "big ball of mud".
Easing the road to DDD
The case for domain driven design might be compelling, but that doesn’t necessarily make it easy to do. Let’s take a look at some of the challenges that DDD throws up and see how Apache Causeway (and its implementation of the naked objects pattern) helps address them.
DDD takes a conscious effort
Here’s what Eric Evans says about ubiquitous language:
With a conscious effort by the [development] team the domain model can provide the backbone for [the] common [ubiquitous] language…connecting team communication to the software implementation.
The word to pick up on here is conscious. It takes a conscious effort by the entire team to develop the ubiquitous language. Everyone in the team must challenge the use of new or unfamiliar terms, must clarify concepts when used in a new context, and in general must be on the lookout for sloppy thinking. This takes willingness on the part of all involved, not to mention some practice.
With Apache Causeway, though, the ubiquitous language evolves with scarcely any effort at all. For the business experts, the Apache Causeway viewers show the domain concepts they identify and the relationships between those concepts in a straightforward fashion. Meanwhile, the developers can devote themselves to encoding those domain concepts directly as domain classes. There’s no technology to get distracted by; there is literally nothing else for the developers to be working on.
DDD must be grounded
Employing a model-driven design isn’t necessarily straightforward, and the development processes used by some organizations positively hinder it. It’s not sufficient for the business analysts or architects to come up with some idealized representation of the business domain and then chuck it over the wall for the programmers to do their best with.
Instead, the concepts in the model must have a very literal representation in code. If we fail to do this, then we open up the communication divide, and our ubiquitous language is lost. There is literally no point having a domain model that cannot be represented in code. We cannot invent our ubiquitous language in a vacuum, and the developers must ensure that the model remains grounded in the doable.
In Apache Causeway, we have a very pure one-to-one correspondence between the domain concepts and its implementation. Domain concepts are represented as classes and interfaces, easily demonstrated back to the business. If the model is clumsy, then the application will be clumsy too, and so the team can work together to find a better implementable model.
Model must be understandable
If we are using code as the primary means of expressing the model, then we need to find a way to make this model understandable to the business.
We could generate UML diagrams and the like from code. That will work for some members of the business community, but not for everyone. Or we could generate a PDF document from Javadoc comments, but comments aren’t code and so the document may be inaccurate. Anyway, even if we do create such a document, not everyone will read it.
A better way to represent the model is to show it in action as a working prototype. As we show with the starter apps, Apache Causeway enables this with ease. Such prototypes bring the domain model to life, engaging the audience in a way that a piece of paper never can.
Moreover, with Apache Causeway prototypes, the domain model will come shining through. If there are mistakes or misunderstandings in the domain model (inevitable when building any complex system), they will be obvious to all.
Architecture must be robust
DDD rightly requires that the domain model lives in its own layer within the architecture. The other layers of the application (usually presentation, application, and persistence) have their own responsibilities, and are completely separate.
However, there are two immediate issues. The first is rather obvious: custom coding each of those other layers is an expensive proposition. Picking up on the previous point, this in itself can put the kibosh on using prototyping to represent the model, even if we wanted to do so.
The second issue is more subtle. It takes real skill to ensure the correct separation of concerns between these layers, if indeed you can get an agreement as to what those concerns actually are. Even with the best intentions, it’s all too easy for custom-written layers to blur the boundaries and put (for example) validation in the user interface layer when it should belong to the domain layer. At the other extreme, it’s quite possible for custom layers to distort or completely subvert the underlying domain model.
Because of Apache Causeway' generic OOUIs, there’s no need to write the other layers of the architecture. Of course, this reduces the development cost. But more than that, there will be no leakage of concerns outside the domain model. All the validation logic must be in the domain model because there is nowhere else to put it.
Moreover, although Apache Causeway does provide a complete runtime framework, there is no direct coupling of your domain model to the framework. That means it is very possible to take your domain model prototyped in Apache Causeway and then deploy it on some other J(2)EE architecture, with a custom UI if you want. This is discussed later on, in deployment options.
Extending the reach of DDD
Domain-driven design is often positioned as being applicable only to complex domains; indeed, the subtitle of Evans book is "Tackling Complexity in the Heart of Software". The corollary is that DDD is overkill for simpler domains. The trouble is that we immediately have to make a choice: is the domain complex enough to warrant a domain-driven approach?
This goes back to the previous point, building and maintaining a layered architecture. It doesn’t seem cost effective to go to all the effort of a DDD approach if the underlying domain model is simple.
However, with Apache Causeway, we don’t write these other layers, so we don’t have to make a call on how complex our domain is. We can start working solely on our domain, even if we suspect it will be simple. If it is indeed a simple domain, then there’s no hardship, but if unexpected subtleties arise, then we’re in a good position to handle them.
If you’re just starting out writing domain-driven applications, then Apache Causeway should significantly ease your journey into applying DDD. And if you have used DDD for a while, then you should find the framework a very useful new tool in your arsenal.
Architecture
This section describes some of the architectural patterns upon which Apache Causeway builds.
Hexagonal Architecture
One of the patterns that Evans discusses in his book is that of a layered architecture. In it he describes why the domain model lives in its own layer within the architecture. The other layers of the application (usually presentation, application, and persistence) have their own responsibilities, and are completely separate. Each layer is cohesive and depending only on the layers below. In particular, we have a layer dedicated to the domain model. The code in this layer is unencumbered with the (mostly technical) responsibilities of the other layers and so can evolve to tackle complex domains as well as simple ones.
This is a well-established pattern, almost de-facto; there’s very little debate that these responsibilities should be kept separate from each other. With Apache Causeway the responsibility for presentation is a framework concern, the responsibility for the domain logic is implemented by your application code.
A few years ago Alistair Cockburn reworked the traditional layered architecture diagram and came up with the hexagonal architecture (also known as/very similar to the Onion architecture):
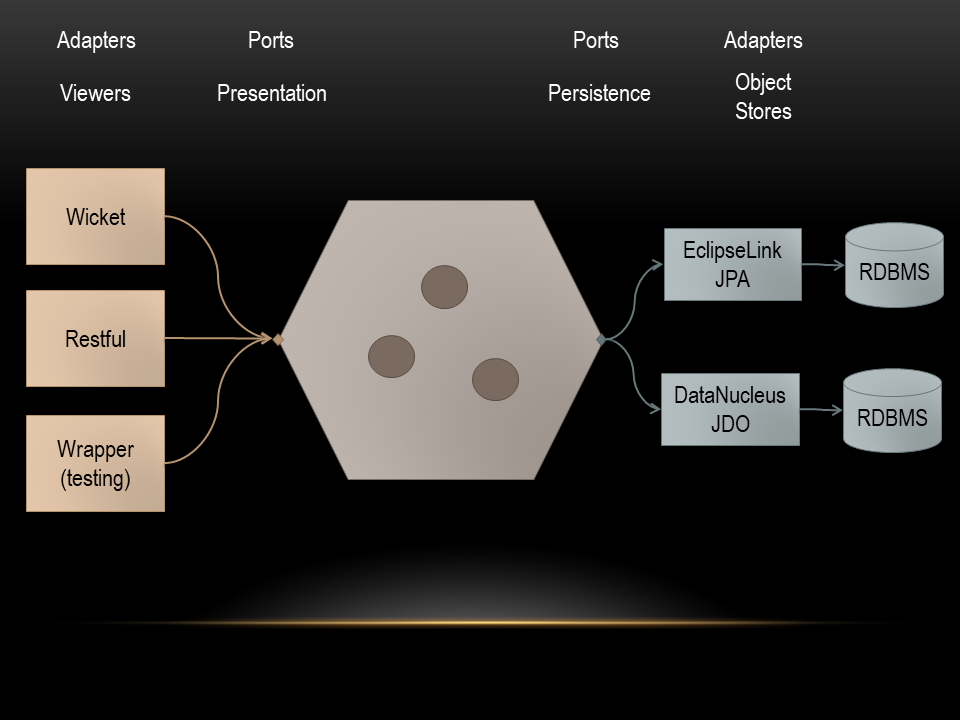
What Cockburn emphasizes is that there’s usually more than one way into an application (what he called the user-side' ports) and more than one way out of an application too (the data-side ports). This is very similar to the concept of primary and secondary actors in use cases: a primary actor (often a human user but not always) is active and initiates an interaction, while a secondary actor (almost always an external system) is passive and waits to be interacted with.
Associated with each port can be an adapter (in fact, Cockburn’s alternative name for this architecture is ports and adapters). An adapter is a device (piece of software) that talks in the protocol (or API) of the port. Each port could have several adapters.
Apache Causeway maps very nicely onto the hexagonal architecture. Apache Causeway' viewers act as user-side adapters and use the Apache Causeway metamodel API as a port into the domain objects. For the data side, we are mostly concerned with persisting domain objects to some sort of object store. Here Apache Causeway delegates most of the heavy lifting to an ORM (DataNucleus or similar).
Aspect Oriented
Although not a book about object modelling, Evans' "Domain Driven Design" does use object orientation as its primary modelling tool; while naked objects pattern very much comes from an OO background (it even has 'object' in its name).
It’s certainly true that to develop an Apache Causeway application you will need reasonably good object oriented modelling skills. But given that all the mainstream languages for developing business systems are object oriented (Java, C#, Ruby), that’s not such a stretch.
However, what you’ll also discover is that in some ways an Apache Causeway application is more aspect-oriented than it is object oriented. Given that aspect-orientation — as a programming paradigm at least — hasn’t caught on, that statement probably needs unpacking a little.
AOP Concepts
Aspect-orientation, then, is a different way of decomposing your application, by treating cross-cutting concerns as a first-class citizen. The canonical (also rather boring) example of a cross-cutting concern is that of logging (or tracing) all method calls. An aspect can be written that will weave in some code (a logging statement) at specified points in the code).
This idea sounds rather abstract, but what it really amounts to is the idea of interceptors.
When one method calls another the AOP code is called in first.
This is actually then one bit of AOP that is quite mainstream; DI containers such as Spring provide aspect orientation in supporting annotations such as @Transactional or @Secured to java beans.
Another aspect (so to speak!) of aspect-oriented programming has found its way into other programming languages, that of a mix-in or trait. In languages such as Scala these mix-ins are specified statically as part of the inheritance hierarchy, whereas with AOP the binding of a trait to some other class/type is done without the class "knowing" that additional behaviour is being mixed-in to it.
Realization within Apache Causeway
What does all this have to do with Apache Causeway?
Well, a different way to think of the naked objects pattern is that the visualization of a domain object within a UI is a cross-cutting concern. By following certain very standard programming conventions that represent the Apache Causeway Programming Model (POJOs plus annotations), the framework is able to build a metamodel and from this can render your domain objects in a standard generic fashion. That’s a rather more interesting cross-cutting concern than boring old logging!
Apache Causeway also draws heavily on the AOP concept of interceptors. Whenever an object is rendered in the UI, it is filtered with respect to the user’s permissions. That is, if a user is not authorized to either view or perhaps modify an object, then this is applied transparently by the framework. The SecMan extension provides a rich user/role/permissions subdomain to use out of the box; but you can integrate with a different security mechanism if you have one already.
Another example of interceptors are the Command Log and Auditer modules. The Command Log module captures every user interaction that modifies the state of the system (the "cause" of a change) while the Auditer module captures every change to every object (the "effect" of a change). Again, this is all transparent to the user.
Apache Causeway also leverages the Spring framework’s event bus. A domain event is fired whenever an object is interacted with, and this allows any subscribers to influence the operation (or even veto it). This is a key mechanism in ensuring that Apache Causeway applications are maintainable, by decoupling logic into separate modules. But fundamentally its relying on this AOP concept of interceptors, with event subscribers in one module potentially influencing or responding to interaction triggered in another.
Finally, Apache Causeway also a feature that is akin to AOP traits. A "contributed action" is one that is implemented by a mixin class but that appears to be a behaviour of rendered domain object. Mixins can also contribute read-only properties or collections: effectively the result of running a query that returns a scalar or a vector. In other words, we can dissociate behaviour from data.
That’s not always the right thing to do of course. In Richard Pawson’s description of the naked objects pattern he talks about "behaviourally rich" objects, in other words where the business functionality encapsulates the data. But on the other hand sometimes the behaviour and data structures change at different rates. The single responsibility principle says we should only lump code together that changes at the same rate. Apache Causeway' support for contributions (not only contributed actions, but also contributed properties and contributed collections) enables this. And again, to loop back to the topic of this section, it’s an AOP concept that being implemented by the framework.
The nice thing about aspect orientation is that for the most part you can ignore these cross-cutting concerns and - at least initially - just focus on implementing your domain object. Later when your app starts to grow and you start to break it out into smaller modules, you can leverage Apache Causeway' AOP support for mixins and interceptors (using the event bus) to ensure that your codebase remains maintainable.
A MetaModel
At its core, Apache Causeway is a metamodel that is built at runtime from the domain classes (eg Customer.java), along with optional supporting metadata (eg Customer.layout.xml).
The contents of this metamodel are the entities and supporting services, as well the members of those classes. These are all meta-annotated with @Component and are either registered explicitly (framework services) or dynamically discovered (entities and user-defined services) by Spring Boot on the classpath via @ComponentScan.
The detail of the metamodel is generally explicit, usually represented by Java annotations such as @Title or @Action, though this is configurable.
Notably the metamodel is extensible; it is possible to teach Apache Causeway new programming conventions/rules (and conversely to remove those that are built in).
Most of the annotations recognized by the framework are defined by the Apache Causeway framework itself.
For example the @Title annotation — which identifies how the framework should derive a human-readable label for each rendered domain object — is part of the org.apache.causeway.applib.annotations package.
However the framework also recognizes certain other JEE annotations such as @jakarta.inject.Inject (used for dependency injection).
The framework integrates with JPA/Eclipselink for persistence.
Apache Causeway recognizes a number of its persistence-specific annotations, for example @jakarta.persistence.Column(nullable=…).
In addition, the framework builds up the metamodel for each domain object using layout hints, such as Customer.layout.xml.
These provide metadata such as grouping elements of the UI together, using multi-column layouts, and so on.
The layout file can be modified while the application is still running, and are picked up automatically; a useful way to speed up feedback.
Apache Causeway vs CQRS/ES
CQRS and Event Sourcing (ES) are two architectural patterns often used (and often used together) to implement domain driven design systems. This section explores the similarities and differences that Apache Causeway has with these other architectural approaches.
CQRS
The CQRS architectural pattern (it stands for "Command Query Responsibility Separation") is the idea that the domain objects that mutate the state of the system - to which commands are sent and which then execute - should be separated from the mechanism by which the state of the system is queried (rendered). The former are sometimes called the "write (domain) model", the latter the "read model".
In CQRS the commands correspond to the business logic that mutates the system.
Whether this logic is part of the command class (PlaceOrderCommand) or whether that command delegates to methods on the domain object is an implementation detail; but it certainly is common for the business logic to be wholly within the command object and for the domain object to be merely a data holder of the data within the command/write datastore.
Most CQRS implementations have separate datastores. The commands act upon a command/write datastore. The data in this datastore is then replicated in some way into the query/read datastore, usually denormalized into a projection such that it is easy to query.
CQRS advocates recommend using very simple (almost naive) technology for the query/read model; it should be a simple projection of the query datastore. Complexity instead lives elsewhere: business logic in the command/write model, and in the transformation logic betweeen the command/write and read/query datastores. In particular, there is no requirement for the two datastores to use the same technology: one might be an RDBMS while the other a NoSQL datastore or even datawarehouse.
In most implementations the command and query datastores are not updated in the same transaction; instead there is some sort of replication mechanism. This also means that the query datastore is eventually consistent rather than always consistent; there could be a lag of a few seconds before it is updated. This means in turn that CQRS implementations require mechanisms to cater for offline query datastores; usually some sort of event bus.
The CQRS architecture’s extreme separation of responsibilities can result in a lot of boilerplate.
Any given domain concept, eg Customer, must be represented both in the command/write model and also in the query/read model.
Each business operation upon the command model is reified as a command object, for example PlaceOrderCommand.
When invoked, this emits a corresponding OrderPlacedEvent.
It is this event that is used to maintain the read model projection.
Comparing CQRS to Apache Causeway, the most obvious difference is that Apache Causeway does not require that the command/write model is separated from the query/read model; there is usually just a single datastore. But then again, having a separate read model just so that the querying is very straightforward is pointless with Apache Causeway because, of course, Causeway provides the UI "for free".
It is possible though to use Apache Causeway in a CQRS style. The entities would have no behaviour in and of themselves to modify their state, they would just be data structures. The behaviour (commands) would instead be implemented as mixins that act upon those commands. In the UI (surfaced by the Web UI (Wicket viewer)) or in the REST API (surfaced by the RestfulObjects viewer) the behaviour appears to reside on the domain object; however the behaviour actually resides on separate classes and is mixed in (like a trait), only at runtime. However, this wouldn’t be true CQRS because those mixins would modify those entities which would then be flushed back to the single database.
Apache Causeway' cross-cutting design does allow for denormalized data stores to be implemented. For example, there are community implementations of Elastic Search database to enable a free-text search (this is likely to be incorporated into the Apache Causeway framework in the future, if it hasn’t already).
There are other reasons why a separate read model might make sense, such as to precompute particular queries, or against denormalized data. In these cases Apache Causeway can often provide a reasonable alternative, namely to map domain entities against RDBMS views, either materialized views or dynamic. In such cases there is still only a single physical datastore, and so transactional integrity is retained.
If you want to go all-in with CQRS with separate databases for the write and read model, then this could still be implemented with Apache Causeway without pulling the framework apart too much. Here, Apache Causeway would be used to provide the UI for the read model, with the entities being truly immutable. Mixins would decorate these entities, but would act upon a write model whose persistence is handled outside of Apache Causeway, probably using Spring Boot directly to provide a datasource. To synchronise the write- and read- model, the events emitted by ExecutionSubscriber could be used.
With respect to commands, Apache Causeway provides the CommandSubscriber which allows each business action to be reified into a Command.
However, names are misleading here: Apache Causeway' commands are relatively passive, merely recording the intent of the user to invoke some operation.
In a CQRS architecture, commands take a more active role, locating and acting upon the domain objects.
More significantly, in CQRS each command has its own class, such as PlaceOrderCommand, instantiated by the client and then executed.
With Apache Causeway, though, the end-user merely invokes the placeOrder(…) action upon the domain object; the framework itself creates the Command as a side-effect of this.
Event Sourcing
The CQRS architecture is often combined with Event Sourcing pattern, though they are separate ideas.
With event sourcing, each business operation emits a domain event (or possibly events) that allow other objects in the system to act accordingly.
For example, if a customer places an order then this might emit the OrderPlacedEvent.
Most significantly, the subscribers to these events can include the datastore itself; the state of the system is in effect a transaction log of every event that has occurred since "the beginning of time": it is sometimes called an event store.
With CQRS, this event datastore corresponds to the command/write datastore (the query/read datastore is of course derived from the command datastore).
Although it might seem counter-intuitive to be able store persistent state in this way (as some kind of souped-up "transaction log"), the reality is that with modern compute capabilities make it quite feasible to replay many 10s or 100s of thousands of events in a second. And the architecture supports some interesting use cases; for example it becomes quite trivial to rewind the system back to some previous point in time.
When combined with CQRS we see a command that triggers a business operation, and an event that results from it.
So, a PlaceOrderCommand command can result in an OrderPlacedEvent event.
A subscriber to this event might then generate a further command to act upon some other system (eg to dispatch the system).
Note that the event might be dispatched and consumed in-process or alternatively this might occur out-of-process.
If the latter, then the subscriber will operate within a separate transaction, meaning the usual eventual consistency concerns and also compensating actions if a rollback is required.
CQRS/event sourcing advocates point out — correctly — that this is just how things are in the "real world" too.
Comparing event sourcing with Apache Causeway, in many ways they are orthogonal and so could in theory be combined. An event sourced entity "rehydrate" the domain object from persistence differently than an ORM, but once that is done, the domain object is in memory to be interacted with. To use Apache Causeway with event sourcing would require disregarding the built-in support for persistence though an ORM, and instead implement some other event sourced persistence mechanism to rehydrate the object. Because Apache Causeway runs on top of Spring Boot, such an integration ought to be comparatively easy to do.
As with a CQRS architecture, Apache mixins would be the obvious way to associate behaviour with an event sourced entity. These mixins would most likely delegate to an event sourcing framework such as Axon to do the work. Also, in Apache Causeway every business action (and indeed, property and collection) emits domain events through the EventBusService, and can optionally also be published through the ExecutionSubscriber. These features could also have a role to play in an event sourced system.
Deployment Options
Apache Causeway is a mature platform suitable for production deployment, with its "sweet spot" being line-of-business enterprise applications. So if you’re looking to develop that sort of application, we certainly hope you’ll seriously evaluate it.
But there are other ways that you can make Apache Causeway work for you; in this section we explore a few of them.
Prototyping
Apache Causeway is great for rapid prototyping, because all you need to write in order to get an application up-and-running is the domain model objects.
By focusing just on the domain, you’ll also find that you start to develop a ubiquitous language - a set of terms and concepts that the entire team (business and technologists alike) have a shared understanding.
If you wish, you could combine this with BDD - the framework integrates with Cucumber.
Once you’ve sketched out your domain model, you can then either start-over and deploy with one of the deployment options listed below.
Deploy with a generic UI
One of the original motivations for Apache Causeway was to be able automatically generate a user interface for a domain object model. The framework’s architecture allows for different user interface technologies. The principal implementation is the Web UI (Wicket viewer), which as well as providing an appealing default user interface also has the ability to be customized the user interface by writing new Apache Wicket components. The framework provides a number of these.
Deploying on Apache Causeway means that the framework also manages object persistence. Again this is pluggable, currently only the JPA (EclipseLink) implementation is supported.
Deploy with custom controllers
If the Web UI (Wicket viewer)'s extensions are too restrictive, another option is to deploy custom controllers/views for specific use cases alongside the generic viewer. This way you can use the generic viewer to deliver the majority of the app’s functionality, but you can justify the additional effort of writing a custom controller for those specialised/high volume use cases where a different flow is needed.
Because Apache Causeway runs on top of Spring Boot, you can easily integrate any of the UI technologies supported by Spring, or of course use Apache Wicket for a similar look-n-feel.
Deploy as a REST API
REST (Representation State Transfer) is an architectural style for building highly scalable distributed systems, using the same principles as the World Wide Web. Many commercial web APIs (twitter, facebook, Amazon) are implemented as either pure REST APIs or some approximation therein.
The Restful Objects specification defines a means by which a domain object model can be exposed as RESTful resources using JSON representations over HTTP.
Apache Causeway' RestfulObjects viewer is an implementation of that spec, making any Apache Causeway domain object automatically available via REST. The set of domain objects can also be optionally restricted to exclude domain entities (thereby avoiding leaking implementation details).
There are three main use cases for deploying Apache Causeway as a RESTful web service are:
-
to allow a custom UI to be built against the RESTful API
For example, using a JavaScript framework such as Angular/Ionic/ReactJs/Vue etc, or JavaFX
-
to enable integration between systems
REST is designed to be machine-readable, and so is an excellent choice for synchronous data interchange scenarios.
The framework provides SPIs to allow custom repreentations to be returned as required.
-
as the basis for a generic UI.
At the time of writing there are a couple being developed, Kroviz (using Kotlin/JS), and Rob (using Microsoft’s Blazor).
Another framework that implements the RO spec is the Naked Objects Framework (on .NET). It provides a complete generic UI tested against its own RO implementation.
As for the human-usable generic UI discussed above, the framework manages object persistence, for example using the JPA/EclipseLink objectstore. It is perfectly possible to deploy the RESTful API alongside an auto-generated webapp; both work from the same domain object model.
Deploy on your own platform
You may be happy to use Apache Causeway for prototyping, but have your own proprietary application framework to actually build production apps.
Apache Causeway supports this, because the programming model defined by Apache Causeway deliberately minimizes the dependencies on the rest of the framework.
In fact, the only hard dependency that the domain model classes have on Apache Causeway is through the org.apache.causeway.applib classes, mostly to pick up annotations such as @Action and @Property.
It’s therefore relatively easy to take a domain object prototyped and/or tested using Apache Causeway, but to deploy on some other framework’s runtime.
If you are interested in taking this approach, then you will need to provide your own implementations of any framework-provided services used by your code.
If your own application framework is based on Spring Boot and using JPA as its ORM, then there is another option. As noted above, Apache Causeway itself runs on top of Spring Boot. You could therefore develop a complete custom UI using one of the regular Spring technologies and run that alongside Apache Causeway - in effect the option described earlier but for every use case, not just selected ones. Apache Causeway continues to manage the object lifecycle and persistence as a thin layer on top of Spring, but your custom UI renders the domain objects exactly as you require.